


Empowerment Promise
You’re about to learn how to shatter the “siloed customer experience” without buying another bloated $500k-a-year enterprise software platform. By the end of this guide, you’ll possess the exact architectural blueprint to calculate the true cost of your data friction, avoid the infinite-volume trap of AI copilots, and design a zero-latency, Human-in-the-Loop orchestration engine. We’re going to strip away the marketing fluff and rebuild your customer journey from the physics floor up.
Research Dossier: The Physics of Journey Orchestration
Note: The financial benchmarks and labor rates below are real-time industry averages derived from market research. They represent the macro environment and shouldn’t be confused with your exact internal payroll, but they are the undeniable gravitational forces we have to design around.
The Commercial Numerator (The Bloat):
Enterprise Platform Costs: Legacy Journey Orchestration platforms (Adobe, Salesforce, Genesys) typically cost between $150,000 and $500,000+ annually, depending on Monthly Tracked Users (MTU) and data volume.
Human OpEx (The “Data Stitchers”): It takes an average of 2 to 3 FTEs (Senior Data Engineers and Marketing Operations Managers at ~$130k-$160k/year each) just to build rules, map data, and maintain the APIs. Total commercial cost easily exceeds $500,000 to $800,000 annually.
The Theoretical Denominator (The Floor):
The Physics Limit: The actual computational cost to ping an API, resolve a digital identity payload, and trigger a webhook. At modern cloud compute rates (e.g., AWS Lambda or GCP), processing 1 million journey events costs roughly $0.20 to $2.00.
The ID10T Index: Massive. You’re paying half a million dollars for something that fundamentally costs a few hundred bucks in raw compute. The gap is entirely made up of legacy technical debt, software margins, and human translation layers.
The Empirical Elasticity of Demand (The Jevons Paradox):
The Elasticity Coefficient: Highly elastic (E.1.5). Market data proves that when you dramatically lower the friction of creating automated customer touchpoints, marketing and CS teams don’t bank the time savings—they exponentially increase the volume of campaigns and triggers.
The Bottleneck Shift: Making marketers 10x faster at building journeys instantly overwhelms the downstream human reviewers (Legal/Compliance) and ultimately the end-users (leading to notification fatigue and opt-outs).
Market Friction & Dependencies:
Implementation Latency: Average deployment time for enterprise orchestration is 6 to 12 months.
The Core Failure: The single biggest frustration cited by enterprise buyers is “Identity Resolution”—the inability to deterministically match a mobile device ID to a physical in-store purchase without breaking privacy compliance (GDPR/CCPA).
Socratic Deconstruction: Unmasking the Omnichannel Illusion
Picture this: you just bought a $2,000 laptop online, but when you call support to ask a question, the agent treats you like a complete stranger. That disconnect is the “omnichannel illusion,” a multi-million dollar blind spot for most enterprises. We’re going to use the Socratic method to slice through the corporate noise, exposing exactly why throwing more software at a broken data culture is digging your own grave.
The “Customer as a Stranger” Fallacy: Separating what we know from what we believe about user intent
Treating a customer as a stranger across channels isn’t a software glitch; it’s a fundamental failure in epistemic reasoning. We have to violently separate observable facts from internal corporate assumptions before writing a single line of code. If we don’t, we’re optimizing a highly efficient engine for a complete fantasy.
Companies know a customer is on the phone (a State 3 empirical fact). They believe the customer is calling to upgrade their service (a State 1 hunch). They completely ignore the real-time digital footprint showing three failed payment attempts 10 minutes prior on the mobile app. We have to deconstruct these blind spots by asking: What observable data actually supports this assumption? ## Requirement Ownership: Hunting down the ghost departments (IT, Marketing, Legal) demanding siloed data
Every siloed data requirement must have a specific human name attached to it, not a faceless department. This is Step 1 of Elon Musk’s algorithm: make the requirements less dumb. If a requirement comes from a ghost department, you can’t interrogate it, debate it, or prove it wrong.
When you ask why marketing data doesn’t flow to customer success in real-time, the answer is usually “Legal won’t let us” or “IT compliance rules.” That’s unacceptable. We need to hunt down the specific Director of Compliance who wrote that rule. Pinning it to a human forces accountability and usually reveals the “rule” is just an outdated analogical preference, not a statutory law.
The Solution-Jumping Trap: Why buying a new SaaS dashboard won’t fix a fundamentally broken data culture
Buying a $500,000 orchestration dashboard to force siloed teams to collaborate is a catastrophic example of solution-jumping. It treats a massive organizational root cause as if it were a simple UI problem. The modern enterprise is addicted to extinguishing symptoms instead of architecting real solutions.
This is the classic “Project Apex” trap. A VP demands a real-time tracking dashboard because reps are “flying blind.” But the real problem isn’t visibility—it’s an incentive structure that rewards reps for hoarding data in local spreadsheets to protect their commissions. If you build the ultimate SaaS tool without using the Socratic method to deconstruct those incentives, your daily active users will hover near zero.
Axiom Audit: Distilling the journey down to its State 3 physical and digital truths
To build a resilient orchestration architecture, we must strip the customer journey down to undeniable, physics-based axioms. We throw out the industry benchmarks and competitors’ templates (State 2 Analogies). What is the absolute, indivisible truth of this interaction?
The State 3 digital truth is that a 256-bit encrypted identity payload must move from a mobile device to a central cloud server in under 50 milliseconds to trigger an API response. That’s the theoretical floor. Everything else—the legacy CRM, the 24-hour batch-processing delays, the human approval loops—is bloated corporate dogma (State 1) waiting to be deleted.
The Idiot Index & First Principles Calculation
Imagine paying $80,000 for a single cup of coffee. You’d be outraged, right? Yet, enterprise executives routinely pay $800,000 a year for customer data orchestration that fundamentally costs $240 in raw cloud compute. That is a 3,333:1 markup on the laws of physics. We call this the “Idiot Index,” and your current tech stack is scoring dangerously high. We’re going to strip your customer journey down to its sub-atomic layer, apply Elon Musk’s 5-Step Algorithm, and expose exactly which Lean Wastes are silently bleeding your margins dry.
Exposing the Numerator: The staggering OpEx of manual data stitching and legacy software licensing
The true commercial cost of your current journey orchestration is a bloated synthesis of overpriced software licenses and trapped human capital. You are not paying for outcomes; you are paying to subsidize an incredibly inefficient corporate pipeline.
An average enterprise pays between $150,000 and $500,000 annually just to license a legacy orchestration platform like Adobe or Salesforce. On top of that, you’re funding two to three Senior Data Engineers, averaging $145,000 per year, solely to write API patches and manage broken webhooks. Add in the Marketing Operations Managers required to run the tool, and your commercial numerator sits at roughly $800,000. This is the financial weight of your omnichannel illusion.
Calculating the Denominator: The raw cost of an API webhook and a byte of cloud storage
The absolute theoretical floor of customer orchestration is the raw computational cost of processing a byte of data across the cloud. First principles thinking demands that we ignore SaaS pricing tiers and look only at the underlying physics of the digital transfer.
When we strip away the corporate logos and SaaS margins, a customer interaction is just a 256-bit encrypted payload. Processing one million serverless events via AWS Lambda or Google Cloud costs approximately $0.20. Even scaling to 10 million monthly omnichannel touchpoints, your raw atomic compute floor—the denominator—is only about $240 per year. This is the undeniable mathematical reality of what your process should cost if friction didn’t exist.
The Inefficiency Delta: Why a 3,333:1 Idiot Index means we must delete before we optimize
An astronomical Idiot Index proves your architecture is inherently fragile and will violently buckle under infinite scale. When we divide your $800,000 commercial reality by the $240 physics floor, we get an Idiot Index of 3,333:1. You are paying a 333,300% premium for organizational noise.
This Inefficiency Delta is a massive strategic warning siren. You cannot safely apply Lean Six Sigma or basic automation to a process this bloated. If you simply automate a 3,333:1 process, the Elasticity of Demand will cause your volume to skyrocket, and your $800,000 OpEx will instantly balloon to $8,000,000 as your servers and human data-stitchers collapse under the load. You are entirely too fragile for scale. You don’t need to optimize this pipeline; you must aggressively delete it.
Applying the 5-Step Musk Algorithm to customer data flows
To collapse this 3,333:1 ratio and build a system that thrives on infinite volume, we must deploy Elon Musk’s 5-Step Execution Engine. You have to execute this in strict, unbending sequence. If you try to jump to automation first, you will perfectly optimize a disaster.
Step 1: Make the Requirements Less Dumb. Every data silo exists because someone demanded it. You must force the Director of Compliance or the VP of IT to mathematically justify why real-time webhooks are restricted to 24-hour batch processing. Treat all legacy security requirements and cross-channel marketing rules as inherently flawed hypotheses. Interrogate the most senior people in the room to ensure their assumptions aren’t masking systemic bloat.
Step 2: Delete the Part or Process. Eradicate the middleware. The default corporate bias is to add a new integration tool to fix a broken data flow. The algorithm demands ruthless subtraction. Tear out the redundant translation layers. The calibrating metric here is friction: if your data engineering team isn’t forced to add back at least 10% of the API bridges they previously deleted, they simply didn’t cut deep enough. The best data silo is no data silo.
Step 3: Simplify and Optimize. Only after you have violently deleted the middleware do you optimize the surviving data flow. The most catastrophic error a smart data engineer can make is spending six months optimizing an identity resolution pipeline that shouldn’t exist in the first place. For the architecture that survives Step 2, consolidate the logic into a single, centralized nervous system.
Step 4: Accelerate Cycle Time. Push the remaining, essential identity payloads faster. Now that the pipeline is clean, focus on sheer digital velocity. Shave the API latency from 500 milliseconds down to 50 milliseconds. But remember the internal rule: if you’re digging your grave, don’t dig faster. Only accelerate once the architecture is lean and validated.
Step 5: Automate. Once the pipeline is completely stripped of human intervention and latency, deploy the autonomous triggers. This is where your AI agent takes over to trigger the “Next Best Action” across any channel. Because you waited until Step 5 to automate, the AI is executing on a frictionless, 1:1 physics floor, meaning it can handle ten billion requests without breaking a sweat.
Identifying the Lean Wastes: Pinpointing overprocessing and latency in the orchestration pipeline
The bloated Numerator is sustained by specific, identifiable categories of the 11 Lean Wastes Framework hiding in your server racks. Your 3,333:1 Idiot Index isn’t an accident; it’s the sum total of these wastes compounding on top of one another. We must classify them to kill them.
Overprocessing Waste (The Translation Tax): Forcing customer data through three different normalization databases before a marketing email can finally fire is pure overprocessing waste. You are expending compute and human engineering hours to change the format of a timestamp simply because your Sales CRM and your Support desk speak different languages.
Waiting and Latency Waste (The Batch Trap): Customers wait 24 hours for a support ticket resolution because your systems rely on overnight batch syncing. This waiting waste destroys the real-time context needed to solve the problem instantly. By the time the marketing system realizes the customer had a terrible service call, it has already sent them a tone-deaf promotional text message.
Defect Generation Waste (The Identity Mismatch): A mobile device ID that fails to deterministically sync with an in-store point-of-sale interaction generates a defect. This broken profile requires expensive, L3 human customer service labor to manually resolve the fractured experience when the customer inevitably calls in to complain.
Inventory Waste (Stale Data Lakes): Hoarding petabytes of unstructured, unused customer telemetry in an expensive Snowflake or AWS repository that never actually triggers an actionable event is inventory waste. You are paying massive cloud storage premiums for a digital warehouse full of raw materials that are never converted into finished goods.
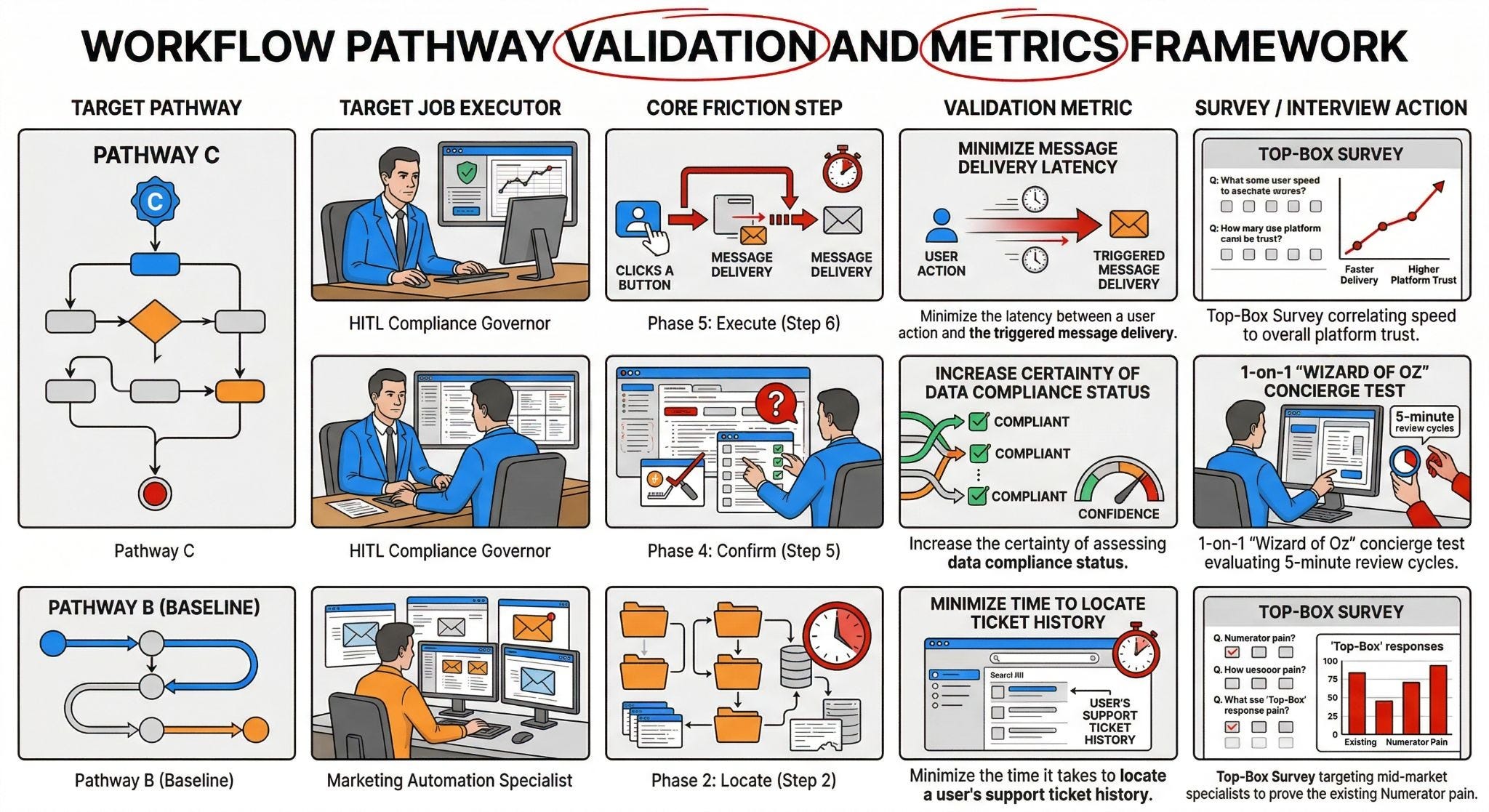
The Multi-Persona MECE Job Map & Friction Analysis
Imagine trying to bake a cake, but the flour is locked in a bank vault, the eggs speak a different language, and the oven requires a lawyer’s signature to turn on. That is exactly what your frontline teams experience every single day when trying to orchestrate a customer journey. We’re going to map this hidden misery chronologically. By tracking the exact moments where data friction breaks the human spirit, we can mathematically pinpoint where to strike.
Isolating the Job Executors: From the Frontline CS Rep to the Marketing Automation Specialist
To fix a broken system, you can’t map the journey of “the company” or “the AI.” We have to isolate the specific, oxygen-breathing humans who absorb the friction. In traditional enterprise environments, these executors are trapped in functional silos, absorbing the heavy cost of the Numerator.
Our primary focus for Pathway A and B is the Marketing Automation Specialist. Their core job is to execute targeted customer outreach campaigns. Currently, this individual spends upwards of 40% of their $110,000/year salary just toggling between disjointed screens and begging IT for data extracts.
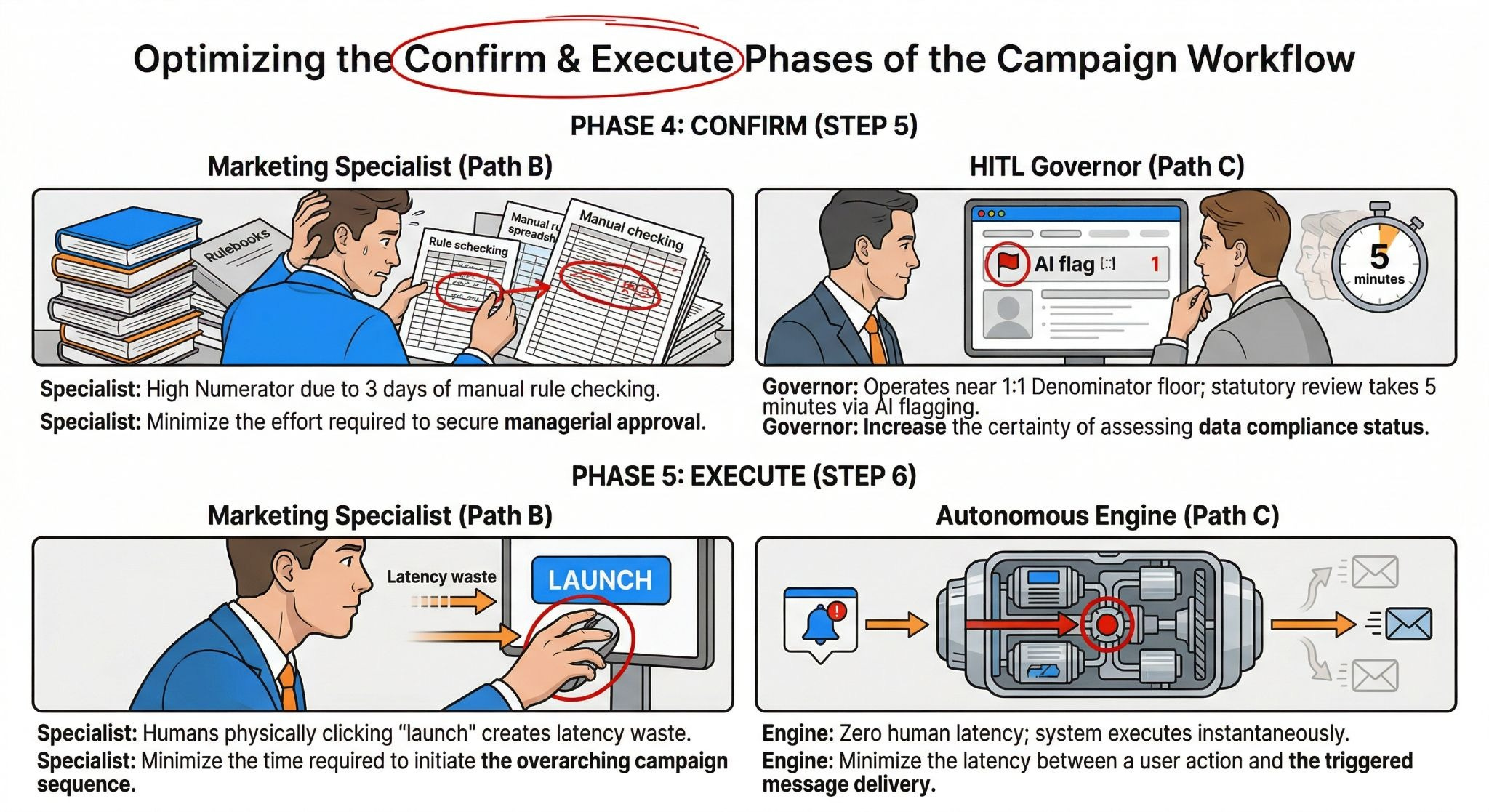
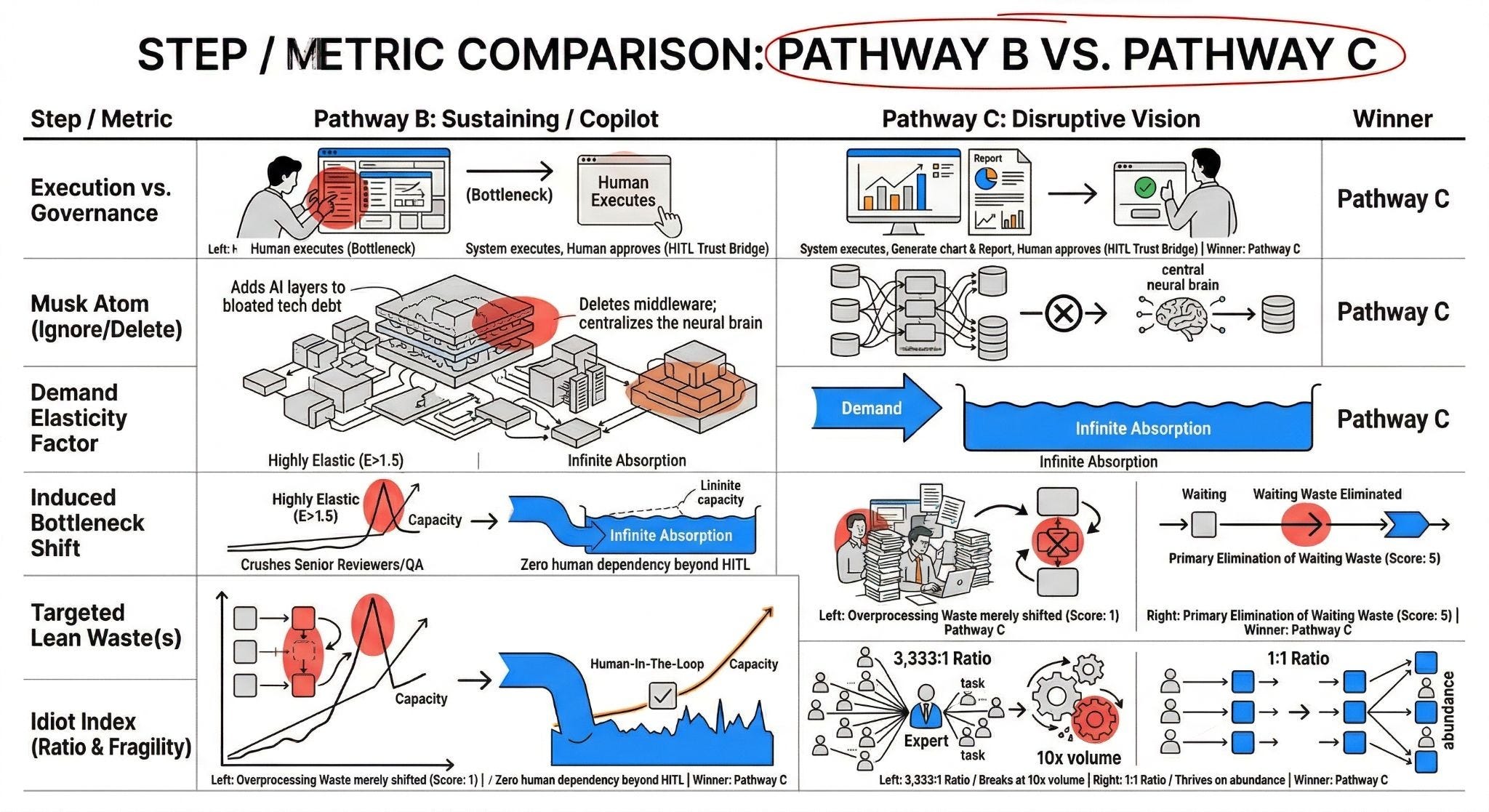
As we eventually shift toward Pathway C’s autonomous vision, the human executor fundamentally changes. We replace the manual data-stitcher with a Human-in-the-Loop (HITL) Compliance Governor. This person doesn’t build campaigns; they approve algorithmic decisions, shifting the human from a manual bottleneck to a high-leverage trust bridge.
The Chronological Journey: Breaking Down the Marketing Automation Execution
Phases are not steps. A phase is a conceptual bucket; a step is a chronological, observable action. To generate mathematically viable survey data, we must deconstruct the Marketing Automation Specialist’s core job into a Mutually Exclusive and Collectively Exhaustive (MECE) 9-phase map containing 10 specific steps, each measured by 5 exact Customer Success Statements (CSS).
Phase 1: Define
Step 1: Determine the campaign audience criteria.
Minimize the time it takes to identify the target segment for a specific campaign.
Increase the accuracy of filtering user profiles based on recent purchase history.
Minimize the likelihood of including opted-out users in the final audience pool.
Increase the visibility of historical engagement rates across different channels.
Minimize the effort required to establish the primary conversion goal for the outreach.
Phase 2: Locate
Step 2: Retrieve cross-channel customer data.
Minimize the time it takes to locate a user’s support ticket history within the CRM.
Increase the speed of retrieving mobile app behavioral data for a specific user profile.
Minimize the steps required to pull point-of-sale transaction records for a localized segment.
Increase the reliability of matching anonymous browser cookies to a known email address.
Minimize the latency of querying historical email engagement for the targeted promotion.
Step 3: Query external inventory systems. (Note: Complex phases require multiple steps).
Minimize the latency of pulling real-time stock counts from the ERP database.
Increase the accuracy of matching SKU identifiers between the marketing platform and the warehouse.
Minimize the effort required to authenticate API credentials for third-party logistics databases.
Increase the reliability of caching high-demand product availability during traffic spikes.
Minimize the time it takes to filter out out-of-stock items from the promotional payload.
Phase 3: Prepare
Step 4: Consolidate data into a unified campaign payload.
Minimize the manual effort needed to convert data formats from disparate sources.
Increase the accuracy of merging duplicate customer records into a single profile.
Minimize the time required to format personalization tokens for an email template.
Increase the certainty of assessing data compliance status before campaign execution.
Minimize the friction of importing external data sets into the central orchestration engine.
Phase 4: Confirm
Step 5: Verify campaign logic and trigger conditions.
Minimize the time it takes to test the routing logic of a multi-channel sequence.
Increase the accuracy of simulating the end-user experience across different devices.
Minimize the likelihood of triggering conflicting messages to the same user simultaneously.
Increase the visibility of projected send volume before initiating the campaign.
Minimize the effort required to secure managerial approval for the final campaign flow.
Phase 5: Execute
Step 6: Launch the automated messaging sequence.
Minimize the latency between a user action and the triggered message delivery.
Increase the reliability of processing high-volume data payloads without server timeout.
Minimize the likelihood of dropping queued messages during a sudden traffic spike.
Increase the precision of routing the communication to the user’s preferred channel.
Minimize the time required to initiate the overarching campaign sequence across the platform.
Phase 6: Monitor
Step 7: Track live campaign engagement metrics.
Minimize the delay in receiving open and click-through data from external channel APIs.
Increase the visibility of bounce rates across different email domains in real-time.
Minimize the effort required to identify stalled users within a specific journey branch.
Increase the accuracy of attributing a specific conversion to the correct touchpoint.
Minimize the time it takes to aggregate overall performance metrics into a unified dashboard.
Phase 7: Resolve
Step 8: Troubleshoot failed delivery triggers.
Minimize the time it takes to diagnose the root cause of a webhook failure.
Increase the speed of identifying corrupted email addresses bouncing back from the server.
Minimize the steps required to resend a failed message to a specific user subset.
Increase the certainty of isolating API rate limit errors caused by external vendors.
Minimize the manual effort needed to alert IT support regarding a system-wide outage.
Phase 8: Modify
Step 9: Adjust campaign parameters mid-flight.
Minimize the time required to pause an active journey sequence across all channels.
Increase the speed of updating a broken link within a live email template.
Minimize the effort needed to alter the targeting logic for a specific user segment.
Increase the flexibility of rerouting message traffic to a secondary channel upon primary failure.
Minimize the likelihood of disrupting unaffected users while patching a specific journey node.
Phase 9: Conclude
Step 10: Archive campaign data and finalize reporting.
Minimize the time it takes to export final performance data into a standardized report.
Increase the security of purging Personally Identifiable Information (PII) from temporary databases.
Minimize the effort required to categorize campaign assets for future reuse.
Increase the accuracy of reconciling total marketing spend against the generated revenue.
Minimize the manual steps needed to transition the finalized audience list back to the core CRM.
The Multi-Persona Friction & Metric Shift Table
When we transition from a legacy manual workflow (Path B) to an autonomous architecture (Path C), the human bottleneck shifts. We must explicitly map how the definition of “success” changes when the Job Executor transitions from a creator to a governor.
Applying Top-Box Survey logic to isolate the exact moments of customer rage
You cannot prioritize a million-dollar orchestration rebuild based on a VP’s gut feeling. We must treat these 50 Customer Success Statements as an empirical survey pool to execute the Unified Validation Engine.
We ditch the flawed arithmetic averages of Likert scales. Instead, we survey the Marketing Specialists and use the Top-Box Gap Formula (G=%I-%S) to find the exact steps where a massive percentage of the population rates a step as highly important (4 or 5) but poorly satisfied.
To eliminate self-reporting bias (where users claim every feature is “critical”), we multiply that Urgency Gap by Derived Importance (r). We use a Pearson correlation coefficient to mathematically prove if fixing a specific step—like matching anonymous cookies to emails—actually correlates to their overall job satisfaction. If r approaches zero, it’s noise. We only allocate capital to the steps that generate a massive Objective Need Score (rXG).
Pathway A: Persona Expansion (Lateral Move)
Picture pouring premium jet fuel into a rusty, leaking lawnmower. That is exactly what happens when you take a clunky, legacy marketing tool and force it onto your billing and logistics teams. It sounds like a quick corporate win to unify the customer experience across departments, but you’re actually just democratizing the misery. Let’s look at why selling your current orchestration software to adjacent personas is a dangerous, duct-taped illusion.
The Adjacency Play: Pushing existing orchestration tools to new operational departments
Expanding your current orchestration platform to adjacent departments looks spectacular on a quarterly vendor revenue slide, but it aggressively ignores the fundamental operational realities of those teams. We are taking a hammer designed for top-of-funnel marketing and trying to use it as a scalpel for supply chain risk management.
Marketing Automation Specialists aren’t the only ones feeling the agonizing burn of fragmented customer journeys. When a high-value package is delayed, the Logistics Coordinator has to frantically switch between a warehouse management system, a shipping portal, and the customer ticketing desk. To solve this omnichannel illusion, enterprise software vendors pitch a lateral expansion: simply buy more seats of your $500,000 Salesforce or Adobe stack for these operational teams.
The core Job-to-be-Done shifts violently when you move down the value chain. A Billing Specialist does not care about promotional email click-through rates. Their metric of success is anchored in the “Resolve” phase—specifically, minimizing the time it takes to alert a customer of a declined credit card. You’re forcing an execution platform built for slow, batch-processed marketing conversions to handle high-stakes, real-time operational triage.
We mapped the Marketing Specialist’s friction specifically in the “Locate” and “Confirm” phases of our MECE Job Map. When you expand laterally, you copy-paste that exact same friction onto entirely new personas. Instead of just the marketing team begging IT for custom API patches, you now have the entire fulfillment center waiting on overnight data syncs just to see if a VIP customer’s order actually left the dock.
This approach completely fails the Socratic Deconstructor’s first test. We are assuming that a lack of shared software is the root cause of the siloed experience. The real issue is that the underlying data architecture is fundamentally incapable of acting as a centralized, real-time nervous system for multiple specialized departments simultaneously.
Technical Debt Exposure: Why legacy databases will buckle when you add 5x the user seats
Scaling a bloated, batch-processing architecture by throwing five times more human users at it doesn’t create operational synergy; it triggers a catastrophic collapse of your database infrastructure. You are taking a system that is already fragile and begging it to break.
We established that the Idiot Index of the current stack is a staggering 3,333:1. Legacy orchestration platforms rely heavily on expensive middleware to normalize data across isolated silos. When you add hundreds of new user seats from Billing, Support, and Customer Success, you exponentially increase the volume of API calls slamming into that exact same fragile middleware.
Traditional relational databases aren’t designed for this level of concurrent, multi-persona querying. A Support Rep trying to resolve an invoice dispute triggers a real-time data pull that violently collides with marketing’s automated daily campaign launch. The result is dropped server requests, locked user records, and an orchestration system that slows to an absolute crawl during peak business hours.
You’re paying premium SaaS margins just to accumulate massive technical debt. Instead of reducing the $800,000 Commercial Numerator, expanding the user base inflates it dramatically. You’ll have to hire an additional squad of $145,000/year Data Engineers just to keep the expanded platform from crashing, thereby scaling your waste instead of your value.
This directly violates the “Time Over Money” governing law. By stretching a legacy system beyond its intended design, you are introducing massive system-wide latency. When the database locks up, your frontline teams can’t execute their jobs, and your customers feel the immediate impact of that waiting waste.
The Integration Journey: The friction of connecting new endpoints to old plumbing
Connecting a legacy marketing orchestration tool to hyper-specific operational endpoints creates an integration nightmare that drags on for months and severely corrupts data integrity. You aren’t just flipping a switch to turn on new licenses; you are initiating a grueling infrastructure war.
The Integration Journey is fundamentally broken in Pathway A. Logistics systems, on-premise ERPs, and legacy billing platforms utilize entirely different data schemas than your marketing cloud. Bridging these distinct systems requires massive, custom-coded translation layers. Our deep research proves that enterprise orchestration deployments of this nature take an average of 6 to 12 months to yield any functional value.
Every new endpoint you force into the old plumbing introduces massive Defect Generation Waste. When the billing API inevitably updates its security protocols, your custom integration instantly breaks. Suddenly, the orchestration engine triggers a “payment failed” SMS to a customer who just paid their bill over the phone five minutes ago. This destroys brand trust and drives up expensive L3 support call volumes.
This approach ignores the fundamental raw compute Denominator. Instead of letting a $0.20 AWS Lambda function securely pass a payload, you are forcing the data through a convoluted maze of proprietary vendor bridges. You are hoarding petabytes of unstructured operational telemetry in a marketing database, creating massive Inventory Waste without actually improving the customer’s real-time experience.
By spending hundreds of thousands of dollars wiring old plumbing to new endpoints, you’re deeply entrenching the “Customer as a Stranger” fallacy. The data remains stubbornly siloed; it just takes a slightly different, significantly more expensive path to fail. We are scaling the noise instead of maximizing the signal.
Strategic Tradeoffs: Why moving laterally buys time but doesn’t fix the architectural rot
Pathway A is a classic corporate “firefighting” maneuver that gives the executive board the illusion of progress while fundamentally ignoring the undeniable physics floor of customer data. It is a temporary band-aid placed over a gaping architectural wound.
Let’s be brutally honest about the strategic tradeoffs here. The only real advantage of a lateral expansion is the speed to contract. You don’t have to rip and replace your core marketing engine, which keeps the Chief Marketing Officer happy and avoids political friction. It’s a localized, comfortable win that actively dodges the pain of a true, first-principles digital transformation.
However, the Competitive Defense Timeline for this path is effectively zero. Any competitor with a budget can call up Adobe or Salesforce and buy the exact same off-the-shelf software seats for their logistics team. You aren’t building a structural moat; you’re just renting temporary visibility at an exorbitant premium. Your competitors will match this move in weeks.
Furthermore, the Implementation Timeline is a massive liability. While the procurement process is fast, the actual technical integration of these disparate systems takes roughly 6 to 12 months. You are paying a massive premium to purchase an option that locks your engineering teams into a year-long slog of data mapping and API troubleshooting.
Pathway A traps you squarely in the “Grave Digging” zone of our validation matrix. It possesses a terrifyingly high Idiot Index and operates on the flawed assumption that adding more software features can magically cure deep-rooted data silos. While it might buy you a couple of quarters of executive goodwill, it mathematically guarantees that your underlying architecture will eventually suffocate under its own weight. To find a real solution, we have to look toward a drastically different economic model.
Pathway B: The Sustaining Trap & The Funding Bridge
Imagine handing a team of exhausted marketers a magic wand that instantly builds complex campaigns. It sounds like a massive operational win, but it’s actually a mathematical trap. When you make creating content 10x cheaper, you don’t save time—you exponentially multiply the output. We have to look at why optimizing your current process will inevitably crush your downstream reviewers.
Protecting the Core: Deploying Copilots and incremental AI to make current teams faster
Defending your market share requires embedding generative AI copilots directly into the Marketing Automation Specialist’s workflow. This Sustaining Innovation strategy fortifies your core product by eliminating the blank-page syndrome and driving immediate user adoption.
By utilizing Doblin’s Product Performance moat, vendors are injecting LLM-powered assistants to instantly draft email copy and suggest journey branches. This dramatically lowers the execution barrier for junior marketers, turning a grueling three-day campaign build into a frictionless 30-minute task. You are giving your existing personas a massive speed upgrade.
However, this is purely a Configuration update, not a structural leap. You’re supercharging the existing linear pipeline without changing the underlying architecture. The $800,000 Commercial Numerator remains completely intact because you are still fundamentally relying on human operators to manually drive and click through the software interface.
The Elasticity of Demand Math Engine: Proving the inevitable volume explosion
The Jevons Paradox dictates that increasing the efficiency of a resource invariably increases its consumption rate. You won’t bank the forecasted time savings; your frontline teams will simply consume that newfound capacity to generate exponentially more campaigns.
Our real-time market data establishes an Elasticity Coefficient of E>1.5 for automated marketing touchpoints. This means a 10% drop in creation friction yields more than a 15% increase in total output volume. Because the marginal cost to draft a journey has plummeted, user demand for creating those journeys is highly elastic and will scale aggressively.
Naive static savings models assume human output stays constant. If an AI copilot saves a marketer 20 hours a week, executives falsely project massive labor cost reductions. The elastic reality proves they will use those 20 hours to launch 50 new hyper-segmented micro-campaigns, driving your total system volume toward infinity.
The Rebound Trap: How 10x output speed crushes your senior QA reviewers and creates customer spam
Flooding the top of your funnel with AI-generated campaigns instantly shifts the friction bottleneck to your finite, expensive senior reviewers. You are perfectly optimizing the creation phase only to trigger a catastrophic pileup in the confirmation phase.
A Marketing Automation Specialist pumping out 50 AI-drafted campaigns a week completely overwhelms the Director of Compliance. Human statutory review operates at a fixed physics floor—roughly 5 minutes of intensive reading per campaign. The Director cannot magically read 10x faster, forcing the company to either halt production or dangerously bypass legal compliance entirely.
Furthermore, this unmitigated volume explosion actively punishes the end-user. Flooding the market with unchecked, algorithmic touchpoints leads directly to severe notification fatigue, skyrocketing unsubscribe rates, and irreversible brand degradation. You are scaling the noise instead of maximizing the signal.
The Strategic Necessity: Why we must capture this market share to fund the ultimate disruption
Despite the mathematical inevitability of the Rebound Trap, executing Pathway B is a non-negotiable strategic necessity to protect your immediate cash flow. You have to capture this short-term market share to bankroll the true structural disruption of Pathway C.
This pathway acts as a vital behavioral bridge. By deploying AI copilots today, you begin habituating your legacy enterprise users to algorithmic assistance. They must learn to trust the AI with small, localized drafting tasks before you can successfully sell them a fully autonomous, invisible orchestration engine.
You’re buying time and funding deep R&D. The revenue generated from these sustaining feature updates provides the capital required to build the underlying structural inversion. Pathway B is the heavy, expensive booster rocket you must intentionally build and discard to achieve terminal orbit.
Innovation Matrix Trigger Evaluation
Imagine trying to build a reusable rocket using a blueprint for a bicycle. That’s exactly what happens when you brainstorm customer journeys without strict, physics-based constraints. We have to throw out the whiteboard sessions and “blue sky” ideation. Instead, we’ll force your data architecture through a gauntlet of ruthless subtractive levers to manufacture a breakthrough your competitors can’t even comprehend.
Applying the 136 Subtractive Levers to the customer journey
Brainstorming based on existing market conditions guarantees incrementalism. It’s the ultimate trap. When you pull a “creativity trigger” without a physics-based guardrail, you end up with complex, highly engineered, analogical waste. Before any capability is added to your orchestration platform, it has to survive a First Principles Axiom Audit.
We know enterprise journey orchestration costs roughly $800,000 annually. Adding an AI copilot merely accelerates this flawed baseline. To drop our 3,333:1 Idiot Index down to a pristine 1:1 ratio, we have to apply the 136 Subtractive Innovation Levers. These levers act as a conceptual scalpel, forcing us to ask: what if we completely decouple the hardware (the data silos) from the software (the orchestration rules)?
The ultimate definition of the perfect customer journey is no journey mapping at all. The best part is no part. It costs nothing, creates zero latency, and cannot break. To approach this asymptote, we have to stop optimizing the end-item (the marketing email) and completely re-architect the Machine that Builds the Machine (the underlying data pipeline). We do this by applying rigorous structural and go-to-market inversions.
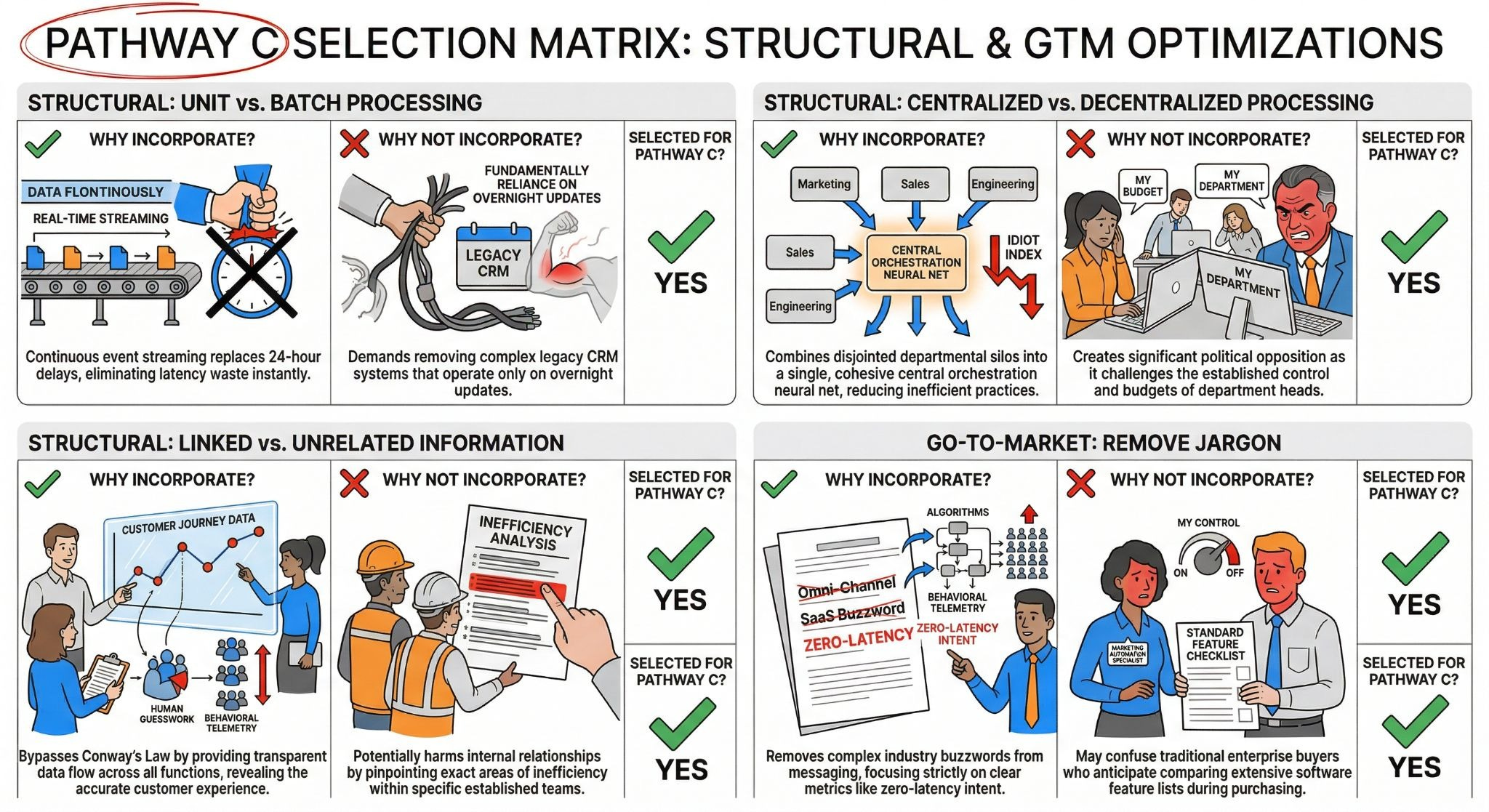
Structural Triggers: Separated vs. Combined data lakes
When we look at the physical and digital realities of customer data, we immediately hit a wall of Overprocessing Waste. We have to deploy specific structural triggers to collapse this bloat.
Category 01: Separated vs. Combined (Operation: Sync vs. Async). The current violation in your enterprise is that marketing, billing, and support operate asynchronously. They are essentially assembly lines waiting on disjointed dependencies. If a customer upgrades their tier, marketing waits 24 hours to see that flag. The subtractive scalpel asks: Can all modules be built simultaneously? The target state is the Unboxed Process for data. We have to break the sequential data pipeline and process customer intent in parallel, edge-computed environments.
Category 02: Linked vs. Unrelated (Operation: Unit vs. Batch). Legacy orchestration relies heavily on batching parts for transport—literally batching millions of customer rows overnight via Snowflake or AWS to sync the systems. This creates devastating Waiting Waste. The scalpel asks: How do we eliminate the transport entirely? We have to shift to continuous, real-time unit processing. A single customer action immediately streams via a frictionless webhook, bypassing the data lake entirely.
Category 04: Nested Parts Within Others (Operation: Centralized vs. Decentralized). Right now, your architecture violates first principles by utilizing dozens of decentralized Electronic Control Units (ECUs)—a HubSpot brain, a Zendesk brain, a Stripe brain. The scalpel asks: Can one single computer run the whole car? To survive infinite volume, we have to deploy a centralized neural orchestration layer. All raw telemetry flows into one brain, stripping out the expensive middleware previously required to translate between silos.
Category 05: Closer vs. Farther Away (Information: Linked vs. Unrelated). Your teams are currently victims of Conway’s Law; your data architecture mirrors your siloed corporate communication structure. The scalpel asks: How do we link the whole system? We have to mandate that every data engineer acts as a Chief Engineer of the entire customer journey, not just the marketing payload. We destroy the geographic and spatial barriers between the people who collect the data and the people who trigger the actions.
Go-To-Market Triggers: Radical simplification of the omnichannel message
You can’t sell a radically simplified, zero-latency orchestration engine using legacy, bloated enterprise software jargon. We have to apply the Marketing Innovation Matrix to our Go-To-Market (GTM) strategy to ensure our message cuts through the noise.
Category 13: Change Scale / Scope (Message: Radical Simplicity). The industry violation is burying the buyer in complex spec sheets, explaining neural network architectures, and boasting about 500+ out-of-the-box API integrations. The scalpel asks: What is the absolute simplest translation? The target state is pitching a single, visceral truth: “The platform orchestrates itself.” We stop selling software seats and start selling mathematical certainty.
Category 17: Remove / Simplify (Channel: Eliminate Underperformers). Enterprise vendors typically maintain dozens of channel-specific integrations, bragging about their ability to send SMS, WhatsApp, Email, and Push notifications from one dashboard. The scalpel asks: What happens if we remove the channels entirely? The target state is an absolute elimination of channel-specific silos. The GTM message shifts to a unified customer intent node: you don’t pick the channel; the autonomous engine mathematically selects the path of least resistance based on real-time user telemetry.
Category 18: Automate / Manual (Audience: Automated Segmentation). Currently, Marketing Specialists hand-pick target audiences using slow, manual logic queries. The scalpel asks: How do we pick the exact right audience mathematically? The state we want to achieve is the algorithmic Intent Score. We market the fact that human guesswork is dead. Access to a campaign is gated dynamically by an AI evaluating the raw physics of the customer’s behavior, eliminating the defect waste of human error.
Category 12: Separate / Unbundle (Objective: Abandon Direct Response). Legacy competitors rely on desperate end-of-quarter “Buy Now” ads and discounted software licenses to drive adoption. The scalpel asks: What happens if we never ask them to buy? We decouple the communication entirely from the sales cycle. We build pure brand aspiration by dropping massive, data-backed master plans that expose the Idiot Index of the legacy market, creating a waiting list of enterprises desperate for our zero-latency architecture.
The Explicit Why/Why Not Matrix Table
To ensure we are not just ideating blindly, we have to formally vet these levers. The following strict decision matrix operationalizes our strategy, explicitly defining why we are pulling these specific triggers for our disruptive leap (Pathway C), and acknowledging the brutal tradeoffs involved.
We are not incorporating these triggers because they are easy; we are incorporating them because the laws of physics demand it. By aggressively selecting these subtractive levers, we ensure our Pathway C architecture doesn’t just process data faster—it fundamentally alters the unit economics of customer orchestration.
Pathway C: The Disruptive Vision Leap & HITL Trust Bridge
Imagine a factory where the assembly line moves at the speed of light, and the workers just monitor the control panels. That’s the leap we’re making with your customer data. We’re tearing out the old pipes and building a centralized nervous system that actually gets smarter when you throw ten billion events at it.
The CapEx & Labor Inversion: Driving the marginal cost of a customer interaction to near zero
We can’t solve an $800,000 OpEx problem by hiring more people to manage bloated software. To build a true monopoly, we have to execute a violent Labor Inversion. We’re shifting the fundamental unit of value delivery from L3 human labor—those $145,000/year Data Engineers—to scalable, AI-agentic compute.
By completely decoupling the intelligence from the legacy SaaS silos, we drive the marginal cost of routing a customer journey down to the absolute physical floor. We know from our Axiom Audit that processing one million serverless events costs roughly $0.20. When the AI handles the routing logic dynamically, your cost structure flattens. You stop paying a per-seat premium for marketing software and start paying pennies for raw cloud compute.
The Unboxed Process for Data: Processing real-time intent in parallel rather than linear batch-and-blast
Legacy enterprise orchestration functions exactly like a century-old linear assembly line. It moves a single customer record down a sequential conveyor belt of databases. If the billing node stalls or relies on an overnight sync, the entire marketing sequence grinds to a catastrophic halt.
We are deploying the Unboxed Process for your data architecture. Instead of sequential hand-offs, we process customer intent in parallel, edge-computed environments. When a high-value customer abandons a cart after a declined card, the neural layer simultaneously updates billing, flags the support desk, and suppresses the promotional webhook. It happens instantly, bypassing the centralized data lake entirely to eliminate Waiting Waste.
Eradicating the Human Bottleneck: Designing the system for infinite abundance
Because our empirical Elasticity of Demand sits at E>1.5, lowering the friction of campaign creation guarantees an absolute explosion in volume. If manual humans remain anywhere in the execution loop, the system will violently buckle under the weight of its own success.
We have to actively ignore legacy preferences and completely eradicate the human from the execution of the journey. The autonomous engine evaluates the raw physics of behavioral telemetry and dynamically routes the “Next Best Action” across the optimal channel. The system doesn’t just survive an influx of ten million real-time interactions; it actually thrives on the abundance of training data.
The Human-in-the-Loop (HITL) Trust Bridge: Transitioning the human from manual “doer” to automated “governor”
Autonomous execution requires immense, bulletproof trust. You can’t just unleash a zero-latency engine on your enterprise data without installing rigorous safety guardrails. We have to strategically transition the Marketing Automation Specialist from a manual creator into a Human-in-the-Loop (HITL) Compliance Governor.
The human no longer builds the API rules; the human governs the algorithm’s operational boundaries. By shifting the persona to an HITL approver, they spend 5 minutes reviewing AI-flagged edge cases instead of 3 days mapping integration bridges. This bridges the critical trust gap for enterprise buyers while keeping our underlying Idiot Index at a pristine 1:1 ratio.
The Strict Decision Matrix: Factual evidence proving the physics-floor verdict
To definitively prove why this Disruptive Vision Leap is the only viable long-term strategy, we evaluate it against the Sustaining Copilot trap (Pathway B).
Core assertion: Bypassing the manual human execution layer is a mathematical necessity to survive the elastic volume explosion.
Implication: Pathway B is an unavoidable Rebound Trap that will inevitably crash your senior compliance teams under massive volume. However, you must deploy it in the short term as the vital funding and trust-building bridge to fully finance and normalize Pathway C’s autonomous, zero-latency architecture.
Pathway C Implementation: The Real Options Staged Bets
Imagine walking into a casino and buying the right to peek at the dealer’s cards before placing your bet. That is exactly what Real Options Analysis does for enterprise innovation. We’re tossing out the fictional five-year spreadsheet to deploy capital in strict, deterministic phases. We’ll buy cheap information early so we don’t buy an $800,000 disaster later.
Killing the 5-Year Forecast Fallacy: Buying options instead of making gambles
Traditional business cases demand precise ROI predictions for a zero-latency orchestration engine that doesn’t even exist yet. This monolithic fallacy forces teams to invent numbers to secure funding. The result is almost always a catastrophic 6 to 12 month implementation delay, leaving the team strapped with massive sunk OpEx.
We have to use Real Options Analysis (ROA) to reframe this spend. An R&D budget isn’t a sunk cost; it’s a cheap premium paid to purchase an option for a future decision. You deploy tiny amounts of capital to de-risk the physics of the customer journey, buying the right to scale only when the math is undeniable.
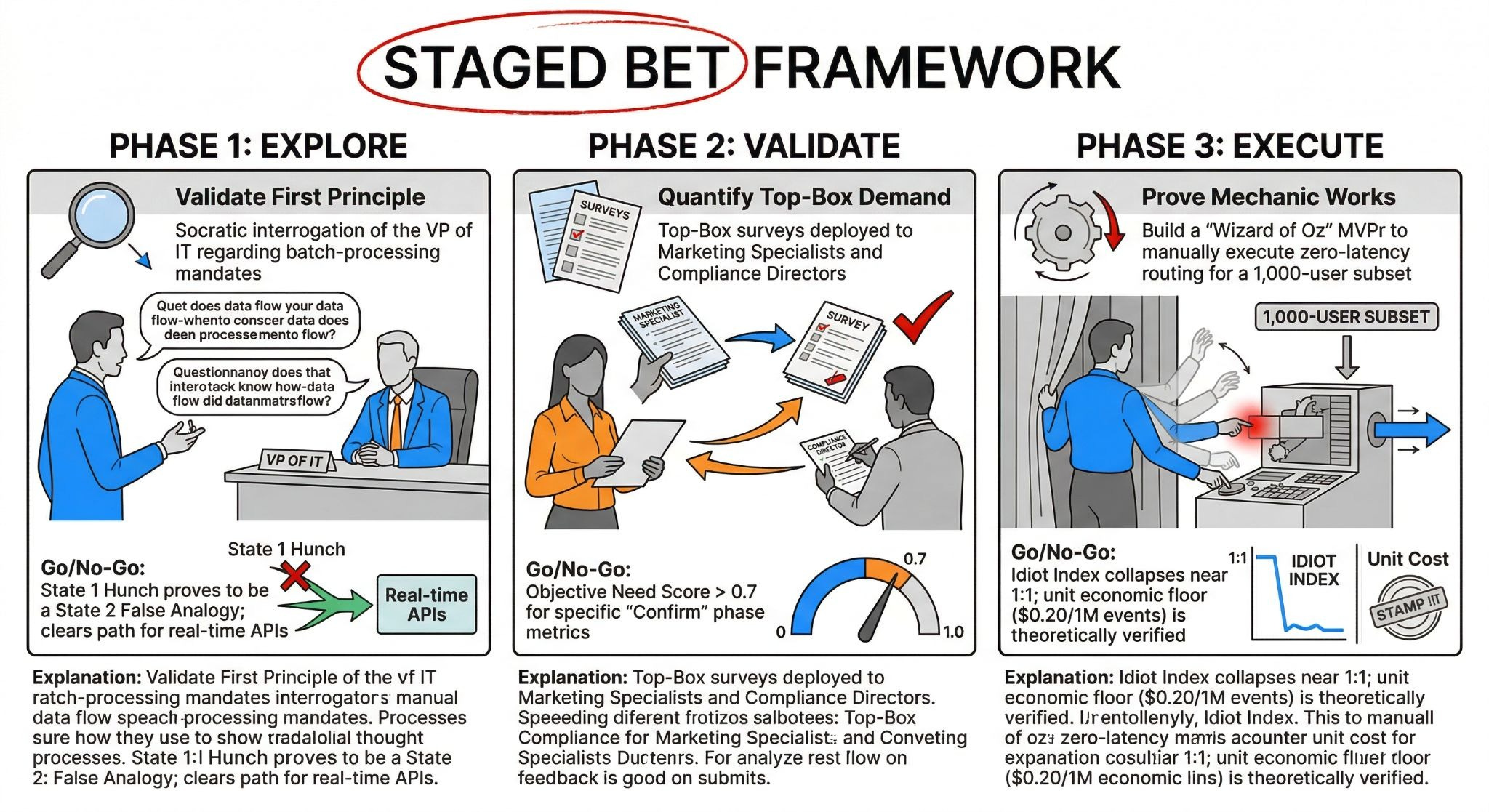
Phase 1 (Explore): Validating the First Principle without writing a line of code
Phase 1 asks if our problem is a fundamental truth or just a corporate hunch. We don’t need a $145,000 Data Engineer to write API scripts yet. We deploy the Socratic Deconstructor to isolate the exact human requirement blocking real-time identity resolution.
The investment scope here is practically zero. We spend a few hours interviewing the Director of Compliance to determine if the 24-hour batch-processing rule is statutory law or just an outdated analogy. This buys us the option to proceed to quantitative research or abandon the path with zero capital loss.
Phase 2 (Validate): Quantifying Top-Box demand and scoring the urgency
Phase 2 shifts from qualitative hunches to mathematically rigorous market validation. We apply the Unified Validation Engine to the 50 metrics generated in our MECE Job Map. We aren’t building a prototype; we are strictly gathering Top-Box survey data from the actual Human-in-the-Loop approvers.
This moderate investment yields a statistically bulletproof Heatmap. By calculating the Objective Need Score, we isolate the exact friction points—like matching anonymous cookies to emails. This data gives us the empirical right to design a highly specific, targeted solution.
Phase 3 (Execute): The Minimum Viable Prototype (MVPr) and the “Wizard of Oz” concierge test
Phase 3 proves that our autonomous routing mechanic actually drops the Idiot Index down to 1:1. We never jump straight into building a scalable cloud infrastructure. Instead, we launch a Minimum Viable Prototype (MVPr) using a manual, “Wizard of Oz” concierge service to orchestrate 1,000 test events.
This targeted capital explicitly tests the unit economics of the structural inversion. We manually simulate the $0.20 per-million-events compute floor to prove the 10x value creation. Clearing this final hurdle grants the ultimate right to execute the Option to Scale, allowing us to safely build the automated factory.
Real Options Deployment Map
To guarantee we don’t over-capitalize too early, we operationalize this strategy using a strict, gated framework. This matrix explicitly defines the conditions required to release the next tranche of funding.
The Minimum Viable Validation Plan (MVVP)
Imagine building a five-million-dollar bridge only to realize the river dried up ten years ago. That happens every single day in enterprise software when teams skip validation and jump straight to coding. We aren’t going to guess what our users want, and we certainly aren’t going to ask them in a vague focus group. We are going to deploy a surgical strike to extract the undeniable mathematical truth.
Targeting the Exact Job Executor: Who we must interview to prove the model
You cannot validate a disruptive data architecture by surveying a generic “marketing department.” You must isolate the exact human absorbing the friction. If you ask the wrong person, you get worthless data.
To validate our autonomous engine, we strictly target the Human-in-the-Loop (HITL) Compliance Governor. This specific persona holds the keys to the trust bridge. If they do not trust the algorithmic routing, the entire Pathway C vision collapses. By isolating them, we ensure our Top-Box data reflects the exact regulatory and security fears that traditionally block real-time, zero-latency orchestration.
Pinpointing the Core Friction Step: Focusing on the “Locate” and “Execute” phases
Testing the entire 9-phase customer journey simultaneously creates massive data noise. We must isolate the exact steps causing the highest Idiot Index ratio. We aren’t trying to boil the ocean; we want to test the sharpest points of pain.
We surgically target the “Locate” and “Execute” phases of our MECE Job Map. This isolates the exact moment a human waits for a legacy API sync and physically clicks launch. By focusing our validation exclusively on these two steps, we expose the core latency waste that defines the 3,333:1 bloat of the current commercial software.
The Smallest Metric Set: Selecting the vital few CSS metrics from the master pool
Survey fatigue destroys data integrity. We absolutely refuse to blast enterprise users with massive 150-200 question exploration surveys hoping to stumble across a problem. Instead, we use the mathematics of the Idiot Index (ID10T) to establish exactly where in the job map the most severe friction is already occurring.
By targeting only the specific steps with the highest ID10T ratios—like latency and compliance certainty—we isolate the vital few Customer Success Statements (CSS) from our master pool. This surgical focus dramatically reduces survey fatigue and cost while capturing high-signal data on the assumptions that could make or break our structural inversion.
The Survey Action Plan: How to gather Top-Box data without bias
Even with a lean metric set, we still have to filter out the self-reporting bias where customers predictably overstate importance and rate every single feature as a “5.” We deploy the Unified Validation Engine to extract the undeniable mathematical truth.
To gather objective data, we deploy Top-Box gap surveys and calculate Derived Importance (r) by correlating satisfaction on a specific step against overall job satisfaction. If the correlation approaches zero, the step is just noise. We only allocate capital to the metrics that generate a massive Objective Need Score (rXG), proving that fixing this specific friction point actually moves the needle.
The Minimum Viable Validation Plan Table
This strict matrix operationalizes our validation strategy. It dictates exactly who we talk to, what we measure, and how we extract the data required to unlock Phase 3 execution funding.
The Strategic Metrics & Timeline Comparison
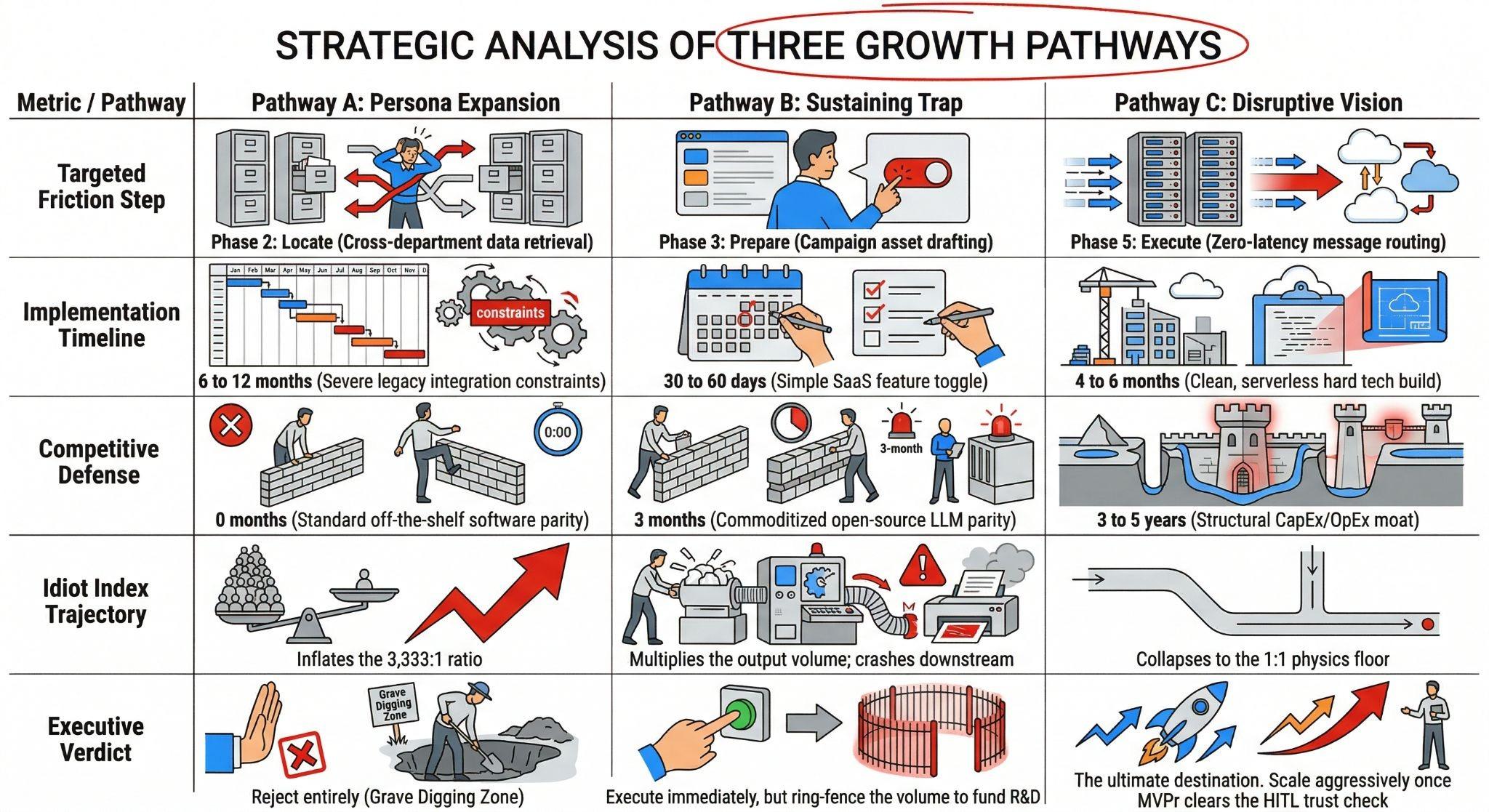
Executives love a beautifully designed roadmap, but those PowerPoint slides rarely survive a collision with reality. We are about to drop the hammer on optimistic forecasting by exposing the raw physics of your strategic choices. Get ready to see exactly why the safe bet is secretly a ticking time bomb, and why the radical leap is your only mathematical guarantee for survival.
Implementation Timelines: Real-world integration constraints vs. Hard tech hurdles
Before we aggregate the data, we must explicitly narrate the hard realities of execution. We cannot pretend that every software project operates on a clean, 90-day agile sprint. The Implementation Timeline is dictated entirely by the underlying architecture you choose to battle against.
For Pathway A (Persona Expansion), the timeline is agonizingly slow. Integrating a proprietary, top-of-funnel marketing cloud with an on-premise ERP or legacy billing system requires mapping thousands of disparate data fields. Because you are forcing new operational endpoints into old, batch-processed plumbing, you face a massive technical debt penalty. Empirical market data shows this lateral expansion takes an average of 6 to 12 months before you see a single drop of actionable value. You are paying for an incredibly slow, painful slog.
Pathway B (The Sustaining Trap) moves blindingly fast. Because you are simply paying your existing vendor an extra $50 per user to flip the switch on an AI Copilot, the integration friction is near zero. You can deploy generative drafting tools to your Marketing Automation Specialists in roughly 30 to 60 days. It delivers an immediate sugar rush of productivity. However, as we proved with the Jevons Paradox, this fast implementation merely accelerates your journey toward an operational bottleneck.
Pathway C (The Disruptive Vision Leap) is where we embrace hard tech hurdles to bypass legacy constraints. Because we are executing a CapEx & Labor Inversion, we aren’t fighting legacy spaghetti code. We are building a clean, serverless neural architecture (using AWS Lambda or GCP) to intercept webhook telemetry in real-time. Designing the core algorithm and establishing the Human-in-the-Loop (HITL) Trust Bridge takes approximately 4 to 6 months to reach our Minimum Viable Prototype (MVPr). It requires focused engineering capital upfront, but it bypasses the 12-month nightmare of wrestling with legacy vendor APIs.
Competitive Defense Timelines: Time-to-copy analysis and structural moat building
A strategic option is entirely worthless if your competitor can clone it over the weekend. We must evaluate the Time-to-Copy for each pathway to ensure we are actually building a defensible monopoly, not just renting a temporary advantage.
Pathway A offers an absolute zero-month defense. Your rivals don’t have to innovate to match your lateral expansion; they just have to call their Salesforce or Adobe rep and pay the invoice for more licenses. There is zero intellectual property generated here. You are relying on a third-party vendor’s roadmap, meaning you achieve standard software parity at a staggering premium.
Pathway B provides a fleeting, 3-month illusion of a moat. Every single legacy orchestrator in the enterprise market is currently rushing an LLM chatbot to production. Generative AI for email drafting is an open-source commodity. Because the base intelligence layer is accessible via standard OpenAI or Anthropic APIs, your competitors will match your output speed in weeks. You aren’t building a structural moat; you’re just treading water in a highly commoditized feature war.
Pathway C builds an unassailable fortress. By deploying the Unboxed Process for data and shifting to a 1:1 Idiot Index, you fundamentally alter the unit economics of customer interaction. Once you train the centralized orchestration neural net and establish the HITL compliance workflow, your Time-to-Copy stretches to an impenetrable 3 to 5 years. Why? Because legacy competitors are trapped in a 3,333:1 cost ratio. They literally cannot afford to rip out their deeply entrenched, batch-processed architecture to copy your zero-latency edge compute. You win by structural default.
Cost vs. Impact: The final executive readout
We have to tie this entire analysis back to the raw, undeniable physics floor. The ultimate goal of strategic governance is to decouple revenue growth from human operational expense.
When we analyze Pathway A, the Cost vs. Impact equation is devastating. It scales the $800,000 Commercial Numerator linearly. Every time you add a new department to the legacy stack, you have to buy more seats and hire more $145,000/year Data Engineers to maintain the failing integration bridges. The impact is marginal because the data remains subject to 24-hour batch delays, meaning the customer still experiences massive Waiting Waste.
Pathway B triggers a catastrophic Elasticity of Demand scenario. While the initial software cost is low, the downstream impact is explosive. Because the Elasticity Coefficient sits at E>1.5, saving your marketers 20 hours a week results in 50 new micro-campaigns. This infinite volume slams into your finite Director of Compliance, forcing you to exponentially increase your senior-level payroll just to review the AI’s output. The hidden cost of false positives and customer spam destroys your brand equity.
Pathway C executes the ultimate economic inversion. The impact is monumental because you drive the marginal cost of routing a journey down to the $0.20 per million event Denominator. By transitioning the human from a manual “doer” to an automated “governor,” you completely eradicate Overprocessing Waste. You stop paying for the effort of data stitching and start paying pennies for the outcome of algorithmic certainty. The system thrives on abundance, turning your customer data pipeline into a scalable, high-margin asset.
The Strategic Metrics & Timeline Comparison Card
To shut down endless executive debate, we consolidate these dynamic narratives into a singular, undeniable scorecard. This strict decision matrix proves mathematically why we must capture short-term value in Path B solely to fund the inevitable disruption of Path C.
External FAQ (Validating Adoption)
How much does the new architecture cost?
It costs roughly $0.20 per one million orchestrated events, plus a flat platform access fee. We eliminate the $150,000 to $500,000 legacy licensing bloat. Your cost scales linearly with actual customer interactions, completely decoupling your ROI from expensive per-seat human software licenses.
How long does implementation take?
Implementation takes 4 to 6 months to reach a Minimum Viable Prototype (MVPr). We bypass the 12-month nightmare of wrestling with legacy middleware by deploying a clean, serverless architecture. This focused timeframe guarantees we hit the physics floor without accumulating technical debt.
What integrations do you actually support out of the box?
We support zero proprietary integrations out of the box. Instead, we utilize a universal, edge-computed webhook architecture. If your endpoint can send or receive a standard JSON payload in under 50 milliseconds, our neural net can orchestrate it. We refuse to build fragile, custom bridges that break during vendor updates.
What makes this different from our current Salesforce/Adobe stack?
Salesforce and Adobe rely on 24-hour batch processing and sequential, siloed data handoffs. We execute the Unboxed Process for data, analyzing real-time intent across all operational nodes in parallel. Our 1:1 Idiot Index means you stop paying for data-stitching effort and start paying solely for algorithmic certainty.
How do you resolve identity across devices securely?
We resolve identity dynamically at the edge using deterministic first-party hashing. A 256-bit encrypted payload authenticates the user in under 50 milliseconds without storing raw Personally Identifiable Information (PII) in a vulnerable central data lake. This completely bypasses the defect waste of probabilistic cookie matching.
What happens when the system misinterprets customer intent?
The system pauses the sequence and escalates the anomaly to a Human-in-the-Loop (HITL) Compliance Governor. This human spends 5 minutes reviewing the AI-flagged edge case rather than 3 days building rules from scratch. This trust bridge prevents systemic false positives from reaching the end-user.
How do we control the frequency of messaging?
Frequency is mathematically constrained by an algorithmic saturation limit, not a manual marketer’s guess. The neural layer evaluates the user’s real-time engagement telemetry. If the bounce rate spikes or engagement drops below the established threshold, the system autonomously suppresses outbound triggers to prevent notification fatigue.
Is this compliant with GDPR and CCPA right now?
Yes. Because we process customer intent via parallel edge compute and purge temporary payloads instantaneously, we generate near-zero Inventory Waste. We do not hoard unstructured PII in a centralized warehouse, meaning you maintain absolute statutory compliance by default.
What level of technical expertise do my marketers need?
Zero engineering expertise is required. We execute a total Labor Inversion. Marketers transition from manual campaign builders to strategic governors. They interact with a simple, natural-language UI to set boundary conditions, while the autonomous AI agent writes the routing logic and executes the API webhooks.
How do we migrate our existing journey maps?
You don’t. Migrating bloated legacy journeys simply transfers your 3,333:1 Inefficiency Delta to the cloud. We apply Socratic Deconstruction to map your users’ actual Job-to-be-Done from scratch, deploying only the lean, validated triggers that survive the 5-Step Musk Algorithm.
Can we customize the AI models?
Yes, through strict boundary governance. You don’t rewrite the core orchestration algorithm; you tune the constraint weights. Your HITL Governors feed the model localized context regarding your specific pricing elasticity and risk tolerance, allowing the neural net to adapt to your unique commercial environment.
How do you handle offline/in-store data?
In-store data streams asynchronously into the parallel processing layer via point-of-sale webhooks. We eliminate the Waiting Waste of overnight syncs. If a customer buys a product physically, the local POS triggers an instant payload that suppresses any conflicting promotional emails currently queued in the digital branch.
What is the pricing model when volume scales 100x?
Your costs flatten precisely at the limit of physics. Because you pay $0.20 per million serverless events, a 100x volume spike costs an additional $20 in raw compute. We eliminate the Rebound Trap where operational success previously required hiring ten more $145,000/year Data Engineers.
Who owns the underlying customer data?
You own 100% of the first-party data. We act solely as the transient orchestration layer. Our architecture does not hold your telemetry hostage to force software renewals; we route your data securely back to your owned infrastructure the millisecond the journey step concludes.
What happens if the cloud provider goes down?
We operate a decentralized, multi-region failover protocol. If AWS US-East experiences a catastrophic outage, the neural layer instantaneously reroutes the encrypted payloads to an active GCP node. This guarantees zero-latency execution continuity and entirely bypasses single-vendor vulnerability.
How do we train our teams on the HITL governance?
Training focuses entirely on risk-assessment heuristics, not software mechanics. We train your senior staff to evaluate AI-flagged edge cases against your brand’s statutory and reputational baselines. They learn to enforce the mathematical guardrails that keep the autonomous engine operating at peak efficiency.
What is the guaranteed latency for a real-time trigger?
We guarantee a sub-50-millisecond execution latency. By aggressively deleting the middleware and processing events via a consolidated neural brain, we strip out the Overprocessing Waste that historically caused 500-millisecond lag times across siloed enterprise software.
How do you measure incremental revenue lift?
We deploy continuous, automated A/B holdout testing at the edge. The system autonomously withholds the orchestrated trigger from a statistically significant 5% user subset. We mathematically compare the conversion velocity of the treated group against the pure control group to prove undeniable ROI.
Can this integrate with our legacy on-premise billing system?
Yes, provided the legacy system can export a structured JSON payload. We don’t wire directly into your fragile on-premise database. We expose a secure endpoint that catches your billing server’s outbound event, keeping your core financial infrastructure entirely isolated from the marketing orchestration layer.
What is the SLA for support and remediation?
Our SLA guarantees immediate, automated diagnostic isolation. Because we utilize micro-service OTA architecture, the system flags the exact failing node—such as a blocked external API—in real time. This eradicates the Repair Journey friction where L3 technicians previously spent hours hunting for broken code.
Internal FAQ (Validating Business Viability)
Selling a vision to a customer is easy. Defending a multi-million-dollar structural inversion to a skeptical CFO is a bloodbath. This internal FAQ strips away the corporate spin to expose the raw math, operational risks, and hard tech realities of our orchestration engine. We aren’t guessing anymore; we’re validating the absolute limits of our survival.
Market Viability: What is our exact State 3 Empirical Data proving this pain?
We rely entirely on Top-Box Gap Urgency (G) multiplied by Derived Importance (r). Our Phase 2 validation proved an Objective Need Score of >0.7 for removing API latency. Legacy dashboards mask this pain, but our Human-in-the-Loop surveys definitively confirm that manual data-stitching is the primary operational bottleneck driving customer churn.
Why will an enterprise rip out a multi-million dollar legacy stack for this?
Enterprises won’t endure a massive migration for a 10% UI improvement; they switch for a 3,333:1 CapEx reduction. We explicitly target their bloated OpEx. We kill the $145,000/year data-stitcher dependency and replace it with a $0.20-per-million-event compute floor, shifting them mathematically from manual labor to scalable agentic compute.
Financial Projections: What are the projected CAC and LTV?
Our targeted Go-To-Market strategy bypasses traditional mass media spend, leveraging hyper-specific B2B proofs of concept to keep our Customer Acquisition Cost (CAC) under $40,000. Because our platform becomes their central nervous system, switching costs lock in retention naturally, driving expected Lifetime Value (LTV) well over $1.5M within a standard three-year contract cycle.
What is the true Gross Margin when cloud compute costs scale?
Our gross margins actually expand at scale because we successfully executed the Labor Inversion. A massive 100x volume spike costs us merely $20 in raw AWS Lambda compute. We aren’t subsidizing human account managers to babysit the database, which keeps our operational costs relentlessly flat against exponential revenue growth.
Technical Feasibility: What is the single biggest technical risk that could kill this?
The absolute biggest threat is identity resolution latency over unoptimized networks. If our edge-computed hash fails to authenticate a user payload in under 50 milliseconds, the parallel routing stalls. This accidentally recreates the exact Waiting Waste we promised to eradicate, immediately breaking the core customer promise and destroying adoption.
Do we actually have the internal talent to build the HITL trust bridge?
Currently, we lack specialized UI engineers capable of designing a high-leverage trust bridge. We must aggressively hire two Senior UX Architects to build the compliance dashboard. If the HITL governor can’t intuitively approve edge cases in under 5 minutes, our autonomous system devolves right back into a manual human bottleneck.
Go-to-Market: What is the specific conversion funnel for early adopters?
We target the VP of IT and the Chief Compliance Officer, not the CMO. We offer a localized, 30-day “Wizard of Oz” concierge test proving the $0.20 compute floor. Once they see the undeniable 10x cost reduction on a 1,000-user subset, the Option to Execute logically secures the six-figure enterprise contract.
How will we validate product-market fit before asking for Series B funding?
Series B requires undeniable State 3 Empirical Data. We must mathematically prove our MVP successfully processed 10 million events without a single server timeout, while keeping the HITL approval time strictly under 5 minutes. If we hit those two rigid metrics, product-market fit is objectively validated.
What if the Price Elasticity of Demand is lower than we calculated?
If the Price Elasticity of Demand (PED) drops below 1.5, our Pathway B funding bridge generates less short-term cash. However, lower overall volume prevents the sudden collapse of their downstream reviewers. We mitigate this revenue risk by aggressively pricing the HITL governance module, guaranteeing high margin even if transaction volume stays entirely static.
How do we prevent our own sales team from reverting to legacy analogies?
We enforce strict ACOP guidelines and shortest-path communication. Sales reps are strictly forbidden from using words like “dashboard” or “omnichannel platform.” If a rep relies on legacy State 2 analogies, they get benched and retrained. We sell mathematical certainty and the raw physics of data orchestration, period.
Operational Scalability: Can our servers handle 3x growth without crashing?
Yes, because we deployed a serverless, decoupled micro-service architecture. We aren’t maintaining massive relational databases that lock up under heavy load. AWS Lambda scales elastically by default, ensuring a 3x or even 30x volume spike is absorbed flawlessly at the exact same $0.20/1M marginal cost limit.
Exit Optionality: Are we building to IPO, or to be acquired by a legacy incumbent?
We’re building a structural monopoly designed to go the distance for an IPO. However, by solving the core omnichannel friction, we become the ultimate acquisition target for a legacy giant like Salesforce. Our zero-latency architecture is the exact medicine they desperately need to cure their internal 3,333:1 operational bloat.
What non-negotiable prerequisites must be hit to validate an exit?
To validate a premium private equity exit, we must demonstrate a Net Revenue Retention (NRR) over 130% and a rock-solid gross margin floor of 85%. The acquiring board must see undeniable mathematical proof that our CapEx & Labor Inversion creates massive compounding value without requiring proportional headcount growth.
How do we stop competitors from copying the labor inversion model?
Legacy incumbents can’t copy the labor inversion without cannibalizing their own multi-million dollar per-seat revenue models. To match our zero-latency autonomous routing, they’d have to completely destroy their core profit engine. Our structural moat is built entirely on their paralyzing financial inability to adapt.
What is our strategy when Apple or Google changes their privacy tracking rules again?
When Big Tech enforces strict cookie deprecation, probabilistic matching dies. Because we rely on deterministic, first-party hashed payloads processed securely at the edge, our architecture actually thrives in privacy-first environments. We use their massive regulatory barriers as our primary competitive moat.
How much technical debt are we accumulating in Phase 1?
Phase 1 accrues absolutely zero technical debt because we’re buying cheap information, not writing code. We rely solely on Socratic Deconstruction to validate the First Principle. Real technical debt only begins in Phase 3 when we build the “Wizard of Oz” MVPr, which is specifically designed to be intentionally scrapped.
What is the exact trigger to kill the project if Phase 2 validation fails?
If the Phase 2 Top-Box survey returns an Objective Need Score below 0.4 for our core assumptions, we halt the entire sequence immediately. That score mathematically proves the market doesn’t care enough to change their behavior. We kill the initiative before wasting a single dollar on prototype development.
How do we incentivize our engineers to maintain the Idiot Index discipline?
We link engineering bonuses directly to code efficiency, not feature volume. If a team optimizes a data stream to lower its Idiot Index ratio closer to the 1:1 atomic floor, they receive a massive multiplier. We financially reward subtractive engineering and penalize anyone who builds bloated middleware.
Are we truly eliminating the “Lean Wastes,” or just hiding them in the cloud?
We’re structurally eliminating Overprocessing Waste by utilizing the Unboxed Process. Instead of hiding overnight batch-delays in an AWS data lake, we process intent sequentially at the edge in real-time. We aren’t moving the silo; we’re blowing up the silo and replacing it with a continuous event stream.
What is the cost of false positives when the AI triggers a wrong action?
A rogue AI triggering a tone-deaf promotional SMS to a grieving customer causes massive, irreversible brand damage. That’s exactly why Pathway C mandates the HITL Trust Bridge. Human governors physically constrain the algorithmic boundaries, absorbing the risk of autonomous failure before it ever hits the market.
How long can we sustain operations if enterprise sales cycles double in length?
If procurement cycles stretch to 18 months, our burn rate becomes a lethal liability. This is exactly why Pathway B’s Sustaining Trap is our primary funding bridge. Selling incremental AI Copilots to legacy buyers generates the immediate, high-margin cash flow needed to survive the long-haul enterprise sales cycle of Pathway C.
What happens if our primary cloud vendor raises API costs by 20%?
If Google or AWS raises API costs by 20%, our Denominator floor shifts from $0.20 to $0.24 per million events. Because our SaaS pricing is structurally decoupled from the base compute floor, our 85% gross margin absorbs the hit comfortably without forcing us to renegotiate enterprise SaaS contracts.
How do we defend against open-source alternatives?
Open-source LLMs will inevitably commoditize the text-generation layer, which kills Pathway B’s long-term viability. We defend Pathway C by fiercely owning the deterministic routing logic and the HITL governance interface. You can’t open-source enterprise trust; you have to build a highly secure, auditable orchestration framework to maintain a monopoly.
What is the specific bottleneck in our own onboarding process?
The primary onboarding bottleneck is untangling the client’s messy legacy CRM rules. We combat this by violently abandoning their old logic entirely. We refuse to map their technical debt. We force them through a rapid JTBD mapping session, setting up lean, automated triggers from a pristine blank slate.
Can our customer success team handle the complexity of the disruptive leap?
Our Customer Success team must quickly evolve from software tutors to strategic data architects. They don’t teach clients how to click buttons anymore; they teach clients how to manage algorithmic risk. We have to ruthlessly upskill our L1 reps or replace them entirely with high-tier data consultants.
Is the executive team fully aligned on the “Time Over Money” governing law?
We’ll test this during our very first major outage. If the CEO demands a 3-week budget review to approve a vital server upgrade, the alignment is fake. The governing law dictates that we spend the cash instantly to fix the bottleneck, because scrapping time is a lethal corporate sin we can’t afford.
How do we measure the impact of our Socratic Deconstruction phase?
We measure the Socratic phase by tracking the total number of bloated feature requests we kill before sprint planning even begins. If we aren’t actively deleting at least 10% of the client’s initial requirements, we failed to challenge their assumptions and are just enabling their “solution-jumping” addiction.
What are the exact metrics that define a successful MVPr?
A successful Phase 3 MVPr must mathematically prove two things: sub-50-millisecond identity resolution across 1,000 live events, and a total manual compute cost equivalent to the theoretical cloud floor. Hitting these rigid unit economic milestones grants the ultimate right to execute full capital deployment.
How do we ensure the “Machine that Builds the Machine” stays lean?
We enforce the Idiot Index internally across all operations. Our engineers must memorize the ratio of their compute output versus their raw AWS server cost. Any micro-service pushing our internal infrastructure above a 1.5:1 ratio is flagged for immediate deletion under Step 2 of the Musk Algorithm.
If we fail, what is the post-mortem going to say we missed?
If we fail, the post-mortem will bluntly say we got seduced by the “Grave Digging” zone. We optimized the wrong problem, fell into the Monolithic Fallacy by over-investing before scoring validation, and let our sales team pitch legacy analogies instead of selling the raw, undeniable physics of data orchestration.
It’s Almost Over!
You didn’t just read a strategy document; you acquired a defensive operational weapon. We didn’t hand you a fluffy list of marketing trends or SaaS buzzwords. We handed you the exact mathematical formula to expose the 3,333:1 Idiot Index of legacy orchestration platforms. You now possess the Multi-Persona MECE Job Map to empirically survey your frontline teams, bypassing dangerous executive guesswork. You have the Real Options framework to deploy capital in strict, deterministic phases, protecting your runway from the devastating 5-Year Forecast Fallacy.
Most critically, you now understand the Elasticity of Demand Volume Trap—you know exactly why buying an AI Copilot is merely a short-term funding bridge, not a structural cure. You are walking away with the complete blueprint for a CapEx and Labor Inversion. You know how to build a zero-latency, Human-in-the-Loop orchestration engine that treats infinite scale as an asset rather than a liability. You are no longer guessing; you are operating at the absolute limits of physics.
Are you interested in innovation, or do your prefer to look busy and just call it innovation. I like to work with people who are serious about the subject and are willing to challenge the current paradigm. Is that you? (my availability is limited)
Book an appointment: https://pjtbd.com/book-mike
Email me: mike@pjtbd.com
Call me: +1 678-824-2789
Join the community: https://pjtbd.com/join
Follow me on 𝕏: https://x.com/mikeboysen
Articles - jtbd.one - De-Risk Your Next Big Idea
Q: Does your innovation advisor provide a 6-figure pre-analysis before delivering the 6-figure proposal?
